Deep Patient, el futuro médico de los pacientes con Inteligencia Artificial
Se prevé que el modelado predictivo con datos de registros médicos electrónicos impulsará la medicina personalizada y mejorará la calidad de la atención médica.

Por Hermes Lavallén.
Los registros médicos electrónicos EHR (electronic health record) son una fuente de datos emergente que permite a los investigadores emplear un enfoque basado en datos para la predicción de resultados de salud y para la estratificación del riesgo de los pacientes. Los métodos de aprendizaje automático se pueden utilizar para identificar patrones subyacentes en los HCE (Historias Clínicas Electrónicas) de un individuo, que pueden predecir su estado de salud futuro.
La inteligencia artificial supera a los modelos estadísticos tradicionales en la predicción a partir de la historia clínica electrónica completa de un paciente. Se prevé que el modelado predictivo con datos de registros médicos electrónicos impulsará la medicina personalizada y mejorará la calidad de la atención médica.
La promesa de la medicina digital se deriva en parte de la esperanza de que, al digitalizar los datos de salud, podamos aprovechar más fácilmente los sistemas de información informática para comprender y mejorar la atención. De hecho, los datos de atención médica de los pacientes recopilados de forma rutinaria se acercan ahora a la escala genómica en volumen y complejidad. Desafortunadamente, la mayor parte de esta información aún no se utiliza en los tipos de modelos estadísticos predictivos que los médicos podrían usar para mejorar la prestación de atención. Se sospecha ampliamente que el uso de tales esfuerzos, si tiene éxito, podría proporcionar importantes beneficios no solo para la seguridad y la calidad del paciente, sino también para reducir los costos de atención médica.
A pesar de la riqueza y el potencial de los datos disponibles, escalar el desarrollo de modelos predictivos es difícil porque, para las técnicas tradicionales de modelado predictivo, cada resultado a predecir requiere la creación de un conjunto de datos personalizado con variables específicas. Se sostiene ampliamente que el 80% del esfuerzo en un modelo analítico es preprocesar, fusionar, personalizar y limpiar conjuntos de datos, no analizarlos para obtener información. Esto limita profundamente la escalabilidad de los modelos predictivos.
Otro desafío es que la cantidad de variables predictoras potenciales en la historia clínica electrónica (HCE) puede llegar fácilmente a miles, particularmente si se incluyen notas de texto de médicos, enfermeras y otros proveedores. Los enfoques de modelado tradicionales han abordado esta complejidad simplemente eligiendo un número muy limitado de variables recopiladas comúnmente para considerar.

Los desarrollos recientes en el aprendizaje profundo y las redes neuronales artificiales pueden permitirnos abordar muchos de estos desafíos y desbloquear la información en el EHR. El aprendizaje profundo surgió como el enfoque preferido de aprendizaje automático en problemas de percepción de máquinas que van desde la visión por computadora hasta el reconocimiento de voz, pero más recientemente ha demostrado ser útil en el procesamiento del lenguaje natural, la predicción de secuencias y la configuración de datos de modalidad mixta. Estos sistemas son conocidos por su capacidad para manejar grandes volúmenes de datos relativamente desordenados, incluidos errores en las etiquetas y una gran cantidad de variables de entrada. Una ventaja clave es que los investigadores generalmente no necesitan especificar qué variables predictoras potenciales considerar y en qué combinaciones; en cambio, las redes neuronales pueden aprender representaciones de los factores clave e interacciones a partir de los datos mismos.
El Sistema de inteligencia artificial llamado Deep Patient (paciente profundo), que fue desarrollado por Mount Sinai, un Hospital en Nueva York que es uno de los hospitales más grandes y respetados de los Estados Unidos, fue clasificados entre los mejores hospitales a nivel internacional por su excelencia en la atención clínica.
Según Riccardo Miotto del Departamento de Genética y Ciencias Genómicas de la Escuela de Medicina Icahn en Mount Sinai, Nueva York:
“El aprendizaje de características no supervisado intenta superar las limitaciones de la definición del espacio de características supervisado identificando automáticamente patrones y dependencias en los datos para aprender una representación compacta y general que facilita la extracción automática de información útil al construir clasificadores u otros predictores. A pesar del éxito del aprendizaje de funciones con texto, multimedia y marketing, así como de la creciente popularidad del aprendizaje profundo (es decir, aprendizaje basado en jerarquías de redes neuronales), estas técnicas no se han utilizado ampliamente con datos EHR. Aquí mostramos que el aprendizaje profundo de funciones no supervisado aplicado al preprocesamiento de datos EHR agregados a nivel de paciente da como resultado representaciones que la máquina comprende mejor y mejoran significativamente los modelos clínicos predictivos para una amplia gama de condiciones clínicas.
Este artículo presenta Un marco novedoso que llamamos paciente profundo; para representar a los pacientes mediante un conjunto de características generales, que se infieren automáticamente de una base de datos de HCE a gran escala mediante un enfoque de aprendizaje profundo. Específicamente, se utilizó una red neuronal profunda compuesta por una pila de codificadores automáticos de eliminación de ruido para procesar los EHR de una manera no supervisada que capturaba estructuras estables y patrones regulares en los datos, que, agrupados, componen la representación profunda del paciente. El paciente profundo no tiene dominio (es decir, no está relacionado con ninguna tarea específica desde que se aprendió sobre un gran conjunto de datos multidominio), no requiere ningún esfuerzo humano adicional y se puede aplicar fácilmente a diferentes aplicaciones predictivas, tanto supervisadas como no supervisadas.”
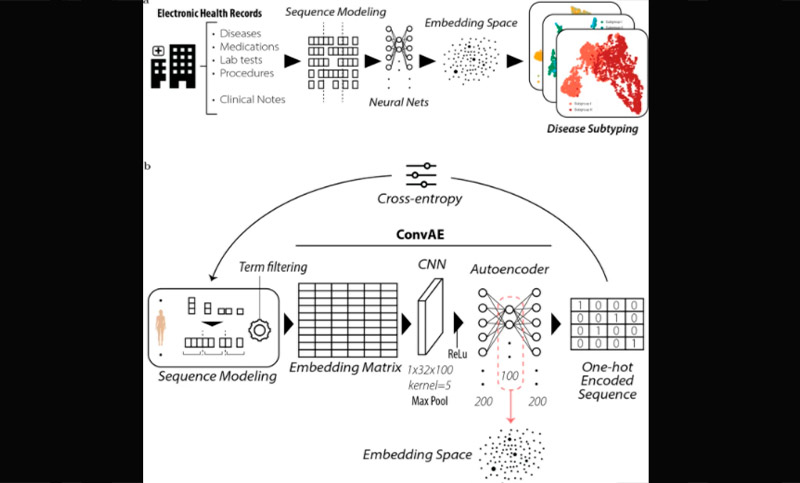
Foto: un marco que permite el análisis de estratificación de pacientes a partir de representaciones profundas de HCE sin supervisión; Detalles de la arquitectura de aprendizaje de representación de ConvAE.
Para entender estos nuevos conceptos de AI (Inteligencia Artificial) y como se relacionan con la ciencia de datos. Se puede empezar por saber cómo son las diferencias de Aprendizaje profundo Vs Aprendizaje automático | AI Vs Aprendizaje automático Vs Aprendizaje profundo. Aquí podemos ver un tutorial de AcadGild sobre ciencia de datos:
Fuentes:
Enlaces: